|
|
5 years ago | |
|---|---|---|
| benchmark | 5 years ago | |
| LICENSE.md | 5 years ago | |
| README.md | 5 years ago | |
| benchmarks.jpg | 5 years ago | |
| go.mod | 5 years ago | |
| go.sum | 5 years ago | |
| main.go | 5 years ago | |
| opengl_boilerplate.go | 5 years ago | |
{kind=link}
README.md
modular-spatial-index-demo-opengl

This demo was based on Golang OpenGL tutorial by kylewbanks.com.
modular-spatial-index
modular-spatial-index is a simple spatial index adapter for key/value databases like leveldb and Cassandra (or RDBMS like SQLite/Postgres if you want), based on https://github.com/google/hilbert.
It's called "modular" because it doesn't have any indexing logic inside, you bring your own index. It simply defines a mapping from two-dimensional space ([x,y] as integers) to 1-dimensional space (a single string of bytes for a point, or a handful of byte-ranges for a rectangle). You can use these strings of bytes (keys) and byte-ranges (query parameters) in any database to implement a spatial index.
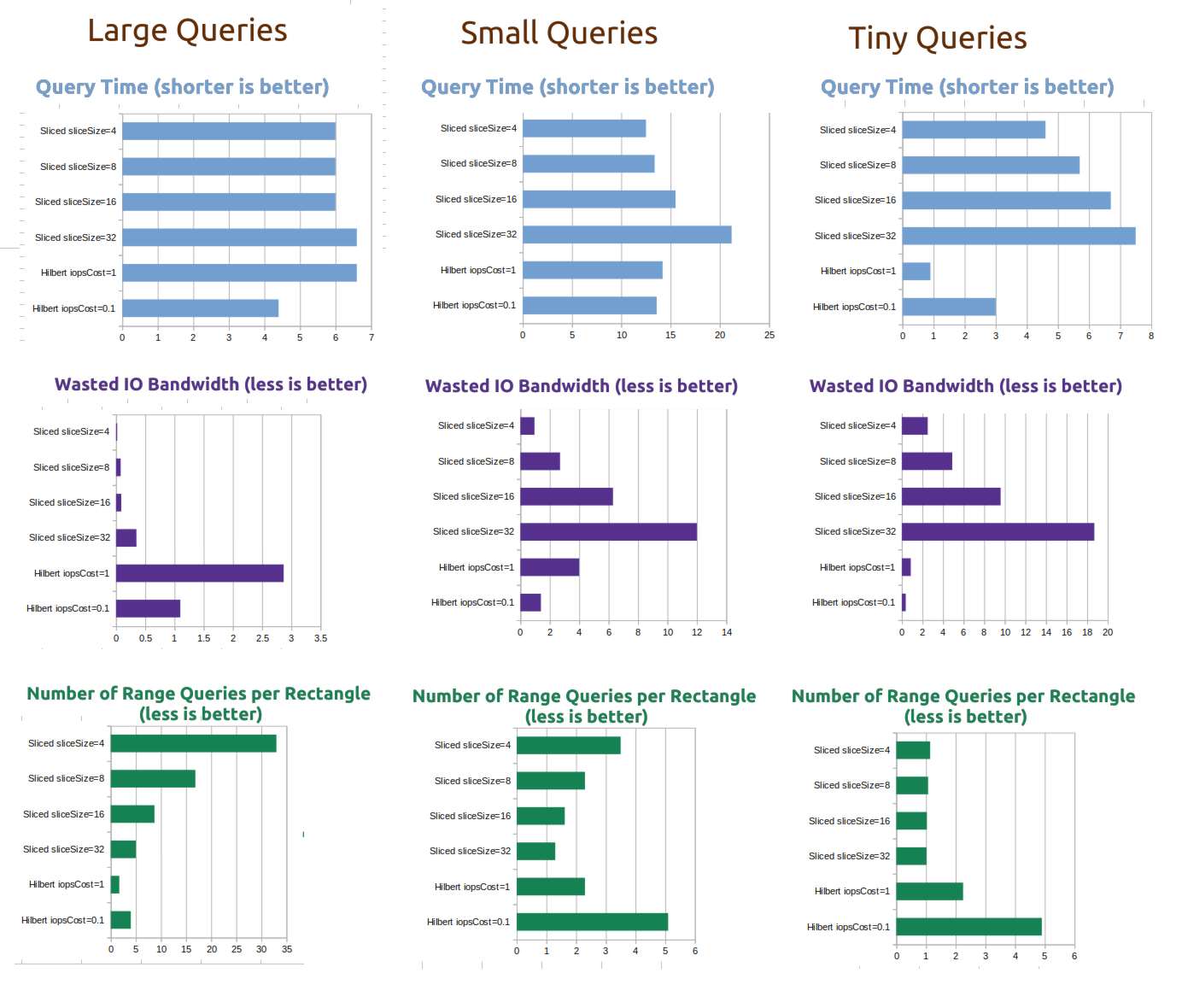
Read amplification for range queries is ~2x-3x in terms of IOPS and bandwidth compared to a 1-dimensional query.
But that constant factor on top of your fast key/value database is a low price to pay for a whole new dimension, right? It's certainly better than the naive approach.
See https://sequentialread.com/building-a-spatial-index-supporting-range-query-using-space-filling-hilbert-curve for more information.
Benchmarks
The benchmarks are part of this repository.
I benchmarked the spatial index against a tuned version of the "One range query for every row in the rectangle" approach I talk about in my blog post linked above, which I am calling the Sliced index, with various slice sizes.
For a test dataset, I used goleveldb to store approximately 1 million keys, each with a 4-kilobyte random value. During the benchmarks, each database index was approximately 3.5GB in size, and the test application was consuming about 30MB of memory.
MIT license